

We tell you everything!
When it comes to search engines, there is still a lot of confusion between meta-search engines that simply display results provided by others in a different interface, and independent search engines that index web content themselves and have their own results ranking algorithms. At Qwant, we have taken the gamble since day one to create a true independent search engine, indexing the Web ourselves and developing our own algorithms, which allow us to provide you with the most relevant information without having to collect your personal data.
This is extremely important in order to guarantee European technological sovereignty. It was indeed abnormal that our knowledge of the Web depended on one or two American actors, who decide for 95% of Europeans what is relevant for their research, imposing their vision and interests.
We have invested heavily in the creation of our index and are investing more and more. At the time of publication, Qwant has in its servers 20 billion indexed web pages, and every day our crawlers go over more than a billion pages to add, delete those that no longer exist, or update all the information that concerns them. Qwant has to our knowledge the largest indexing capacity in Europe.
However, you still read too often that Qwant uses Bing, as if Qwant were just a simple meta-engine that does not have its own technologies. This error was relayed, for example, by the legal blog Precisement.org, which makes a seemingly simple comparison between Bing’s results and those of Qwant, without knowing how things actually work in the background. He notes that 51% of the results are identical, which in passing shows that 49% are different. ” The index of Qwant and its search technologies, according to all appearances (…) are provided by Microsoft’s Bing ,” he wrote.
Fortunately, this is not the case! Here is for example what a small piece (2000 links) of what Qwant indexes on Precisement.org looks like. It is a visual representation generated with Graphee, an internal tool that has been developed and distributed in open-source, which allows to visualize the links between the pages of a website or between different websites:

Each point you see on the image corresponds to a page of the site, to which is associated a weight calculated by our algorithms to determine the importance of the page.

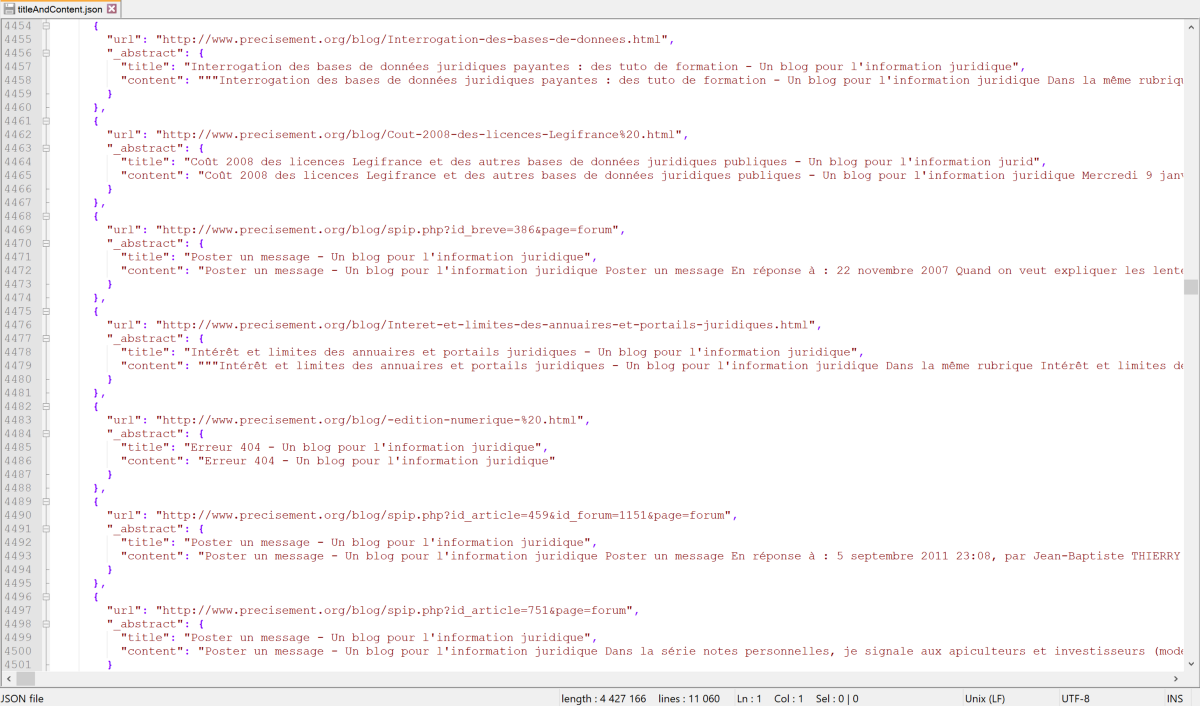
These points are generated from the indexing data. For example, here is a CSV snippet that currently lists more than 6100 referenced pages with links to Precisement.org:

And of course, we store a copy of the content of the site to index it and evaluate its relevance to the keywords searched by our users:
Tens of millions of sites are present in our index and we come back to them very often with our crawlers (more often for large and very popular sites, less often for small sites rarely updated). In reality, Qwant uses Bing to supplement search results on which we do not have sufficient relevance, and on images where storage capacities are very important. On the rest, the main SEO logics are often the same which explains why you often find the same search results, ranked slightly differently according to the weight given to one or the other. But we are evolving our algorithms every day. The switch towards total independence is therefore gradual, and this is indeed the direction taken by Qwant, difficult to see from an outside eye!