



We are working on these approaches since years now and we will explain how we can adapt this work to our industrial needs and how we benchmark them, which led us to a publication in one of the top NLP conference this year: COLING 2020.
In AI one of the main challenges is to let computers understand human speech through vocal assistant, for instance. These spoken dialogues systems are interfaces between users and services, such like: chatbots or vocal assistants, which can allow users to order goods, manage your agenda, find your way, answer cultural questions, book trains, flights, restaurant, etc. Dialogue systems are composed of several modules. The main modules include Automatic Speech Recognition (ASR), Spoken Language Understanding (SLU), Dialogue Management and Speech Generation (Figure 1). Today, we will focus on the Spoken Language Understanding the component of dialogue systems which aims to understand human needs.
Nowadays spoken Language Understanding (SLU) is part of many applications but, a few companies out of GAFAM or BATX, provide such service., and have expertise in such difficult domain to handle.
Coming from a long history of Theorical Linguistic, SLU has several declinations and can have several aspects. One of these aspects is the possibility to link a word or a sequence of word to a meaning, or a concept. This is where this work is focusing.
[1] COLING2020, the 28th international Conference on Computational Linguistics is one of the top conferences in Natural Language Processing.

We, at QWANT, are working on these approaches since years now, and we propose in this article to get deeper into the topic and the technique of SLU. We will also explain how we can adapt this work to our industrial needs and how we benchmark them, which led us to a publication in one of the top NLP conference this year: COLING 2020.
The semantic interpretation made by a computer is a process of conceptualisation of the world using a tool to create a structure of representation of meaning, from different symbols and their characteristics present in words or phrases. Spoken language Understanding is the interpretation of these symbols include in the speech.

This representation aims to translate natural human language into a computer interpretable form, which aims to query a database, for example. This step is crucial in a vocal assistant and dialogue system, and is a part of the intelligence of the system, which extract the very meaning of a sentence.
Several systems and several approaches exist since years and are continuously evaluated against classical understanding tasks. One of these SLU tasks is the MEDIA task, described in the following part.
The French MEDIA task aims to evaluate SLU though a spoken dialogue system dedicated to providing touristic information and hotel booking service. The are more than 1 250 dialogues, have been recorded, transcribed, and annotated manually to prepare this evaluation. Created in 2005 for a French evaluation campaign called TECHNOLANGUE/EVALDA/MEDIA[1], many system have been evaluated since years, which lead to become a key reference in the world of spoken language understanding.
In the Figure 2 is presented an example of applied SLU to a sentence in the MEDIA corpus. Identified recently as one the most challenging SLU task[2], we investigate and tune our models to perform the best, within this framework. Our SLU models will address this challenge.
We decided to challenge the French MEDIA task, using cutting edge approaches that exists in NLP. Most of these approaches have been successfully applied to English corpora, but few of them have been tested on a morphological richer language like French. Most of these models are studied and applied since years at Qwant, which uses recent advances in Artificial Intelligence models: a Neural Network. The first one uses ordered sequences of both words and characters as input to label ordered sequences of words (also known as sequence-to-sequence approach). The input is given to a specific neural network model (a convolutional layer), which extract features and give it as input to another one (a Bi-LSTM ), which encodes it and propose its output to a decoder and decision layer (a CRF ). This model was proposed originally by Ma and Hovy [3], which we adapted and modified to our needs.
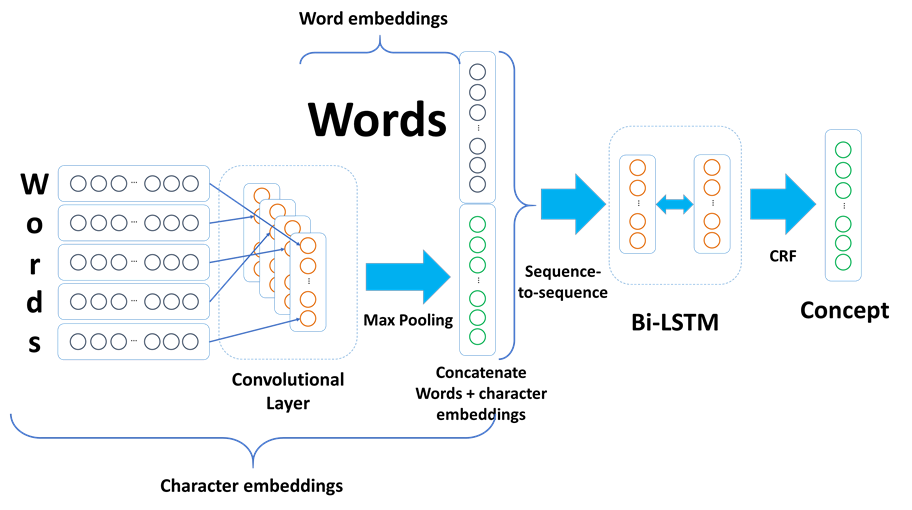
[2] BiLSTM stands for Bi-directional Long-Short-Term-Memory model
[3] CRF stands for Conditional Random Fields
The second model used is the famous BERT model and especially it French French version CamenBERT, proposed by a French research team from INRIA (ALMAnaCH)[4]. This last model is a pre-trained model, which used more than 190Go of data to be trained. This model was downloaded and adapted to our task (or “fine-tuned”). These two models will be benchmarked on the MEDIA French task.
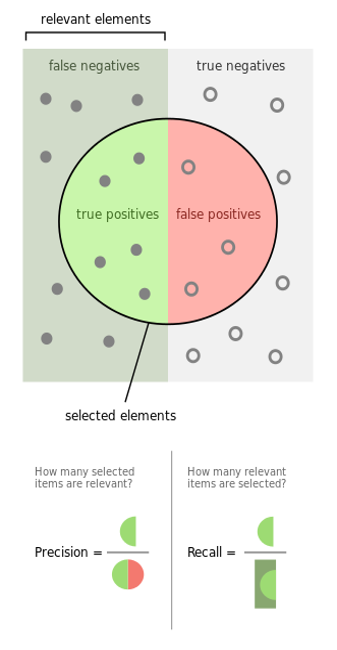
To evaluate our models on the SLU task, we need to use two metrics, the first one is a concept error rate (CER), which indicates the rate of the error between a hypothesis and a reference (the lower the better). The second one is a F-measure, which is a mean between the precision and the recall metrics. The precision indicates how many selected solutions are relevant, the recall is how many relevant items are selected (See Figure 4). If we were fishing, precision would be associated with angling, and the recall with netting. For precision, recall and, F-measure: the higher the better.
The Table 1 shows the results obtained on the MEDIA task according the F-measure and the CER. SOTA indicated the actual State-of-The-Art in the scientific literature, BiLSTM-CNN-CRF refers to the first model described in the Model section. Finally, the best approach is the Fine-tuned CamemBERT, which enable to create real breakthrough in this task.

While Qwant classical model stands a little behind the State-of-the-Art, the French version of BERT enable us to improve of nearly 2 points of CER and more than 1.4 points of F-Measure.
Nowadays even with powerful servers, putting at scale BERT-like is a complex task. Especially when inference time is crucial. Especially when we set up as industrial challenge to process 1 000 queries per second (1ms to answer query). The in-production version of our BiLSTM-CNN-CRF can reach 20ms per query, without any optimisation. In the meanwhile, we are working on fine-tuned BERT models to enable their use in production.
The scalability problem is one of the most important bottlenecks in using Artificial Intelligence in compagnies. This problem has been addressed by many researchers and engineers, most of the time the solution resides in reducing the complexity of the model, jointly with a quantization operation. This last operation aims to reduce the computational representation of number in a model (from 32bits to 8bits, most of the time).
We, at Qwant, are working on these optimisation techniques to let these models match our challenges. We do believe they can improve our search engine results and enhance the user experience.
This work was fut co-authored by Sahar Ghannay, Sophie Rosset (Université Paris-Saclay, CNRS, LIMSI) and Christophe Servan (Qwant). This work has been partially funded by the LIHLITH project (ANR-17-CHR2-0001-03), and supported by ERA-Net CHIST-ERA, and the “Agence Nationale pour la Recherche” (ANR, France).
[1] Helene Bonneau-Maynard, Sophie Rosset, Christelle Ayache, Anne Kuhn, and Djamel Mostefa. “Semantic annotation of the french media dialog corpus”. In the Proceedings of the European Conference on Speech Communication and Technology (Eurospeech), Lisboa, Portugal, 2005.
[2] Frédéric Béchet and Christian Raymond. “Benchmarking benchmarks: introducing new automatic indicators for benchmarking spoken language understanding corpora”. In Interspeech, Graz, Austria, 2019
[3] Xuezhe Ma, and Eduard H. Hovy. “End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF.” In the Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016.
[4] Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suárez, Yoann Dupont, Laurent Romary, Éric de la Clergerie, Djamé Seddah, Benoît Sagot. “CamemBERT: a Tasty French Language Model”. In the Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020.



